There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

In Part 2 of this AI series, we explored how raw data becomes tokens, and how tokens become numerical inputs that flow into a neural network.
Now we go one step deeper — into the engine room of AI training:
👉 How do thousands of GPUs work together to train one model?
👉 Why does training take months, sometimes years?
👉 What makes this process so communication-heavy and complex?
To understand this, we need to imagine what’s happening under the hood during a large-scale LLM training run.
Modern training sets contain:
No single GPU can hold the entire dataset.
No single GPU can hold the full model either.
So the training process is distributed.
The training set is broken into shards and spread across hundreds or even tens of thousands of GPUs.
Example:
If training uses 100,000 GPUs, each GPU holds a small portion of the data.
Each GPU processes its own slice of the training batch.
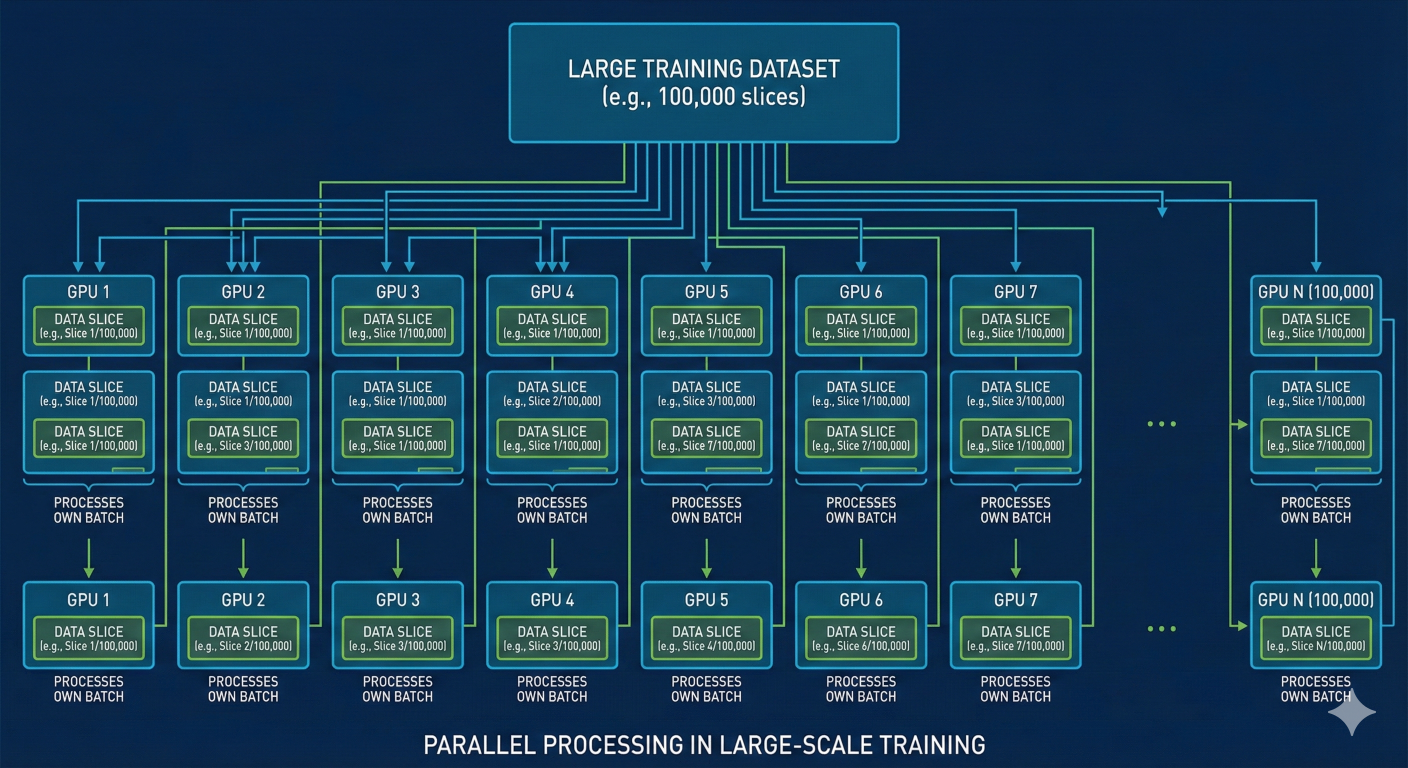
This means:
Training doesn’t just split the data —
it also splits the model.Large models have:
Training doesn’t just split the data —
it also splits the model.Large models have:
3. Training Is an Interactive, Iterative, Multi-Wave Process
Here’s the part most people never hear:👉 Training is not a one-pass operation.
👉 It is an iterative process with millions of calculation waves.Each wave looks like this:
4. Why AI Training Is Extremely Communication-Intensive
Now we reach the heart of this blog.During each training step:
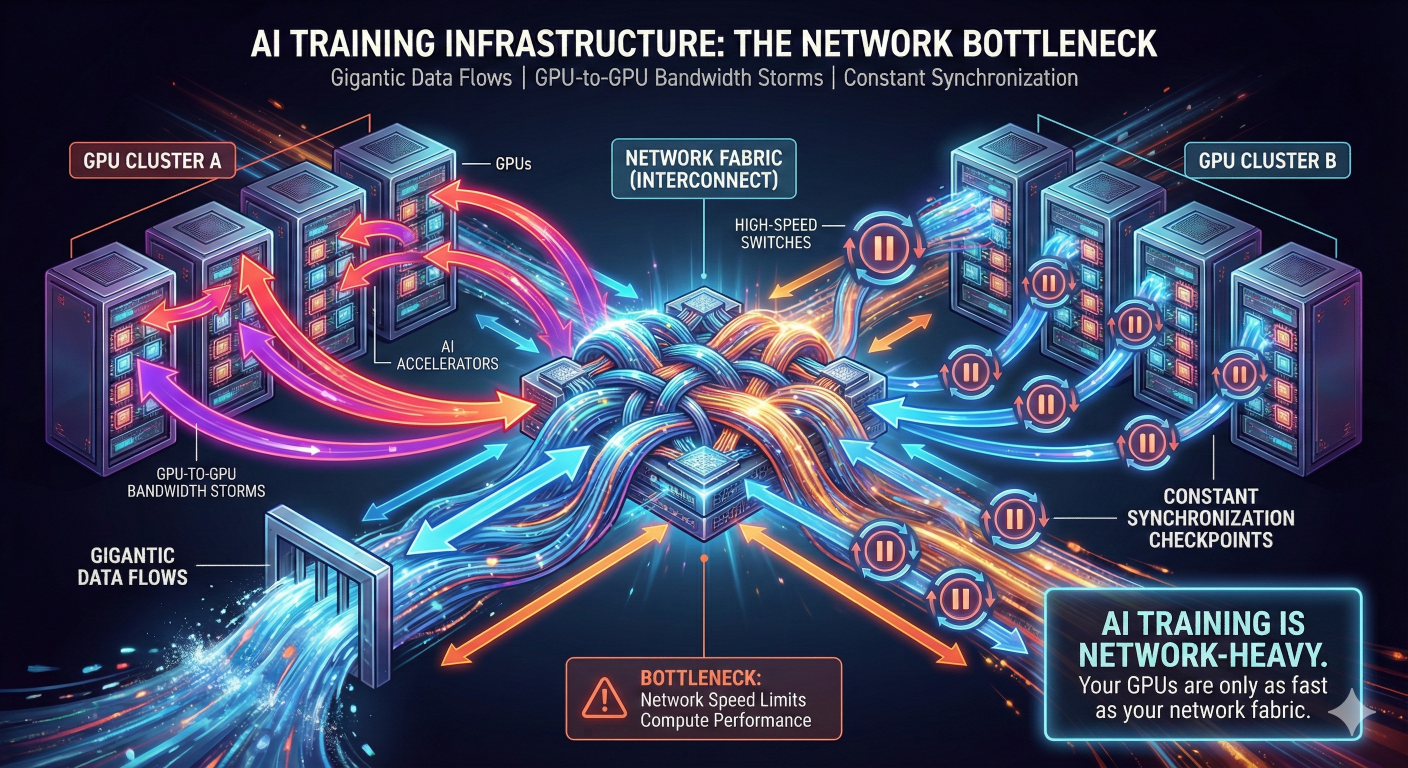
5. The Barrier Method — A Critical Concept
Training uses a synchronization strategy called a barrier method.Here’s what it means:
6. Massive GPU-to-GPU Data Transfer — The Real Bottleneck
During each iteration, GPUs exchange:
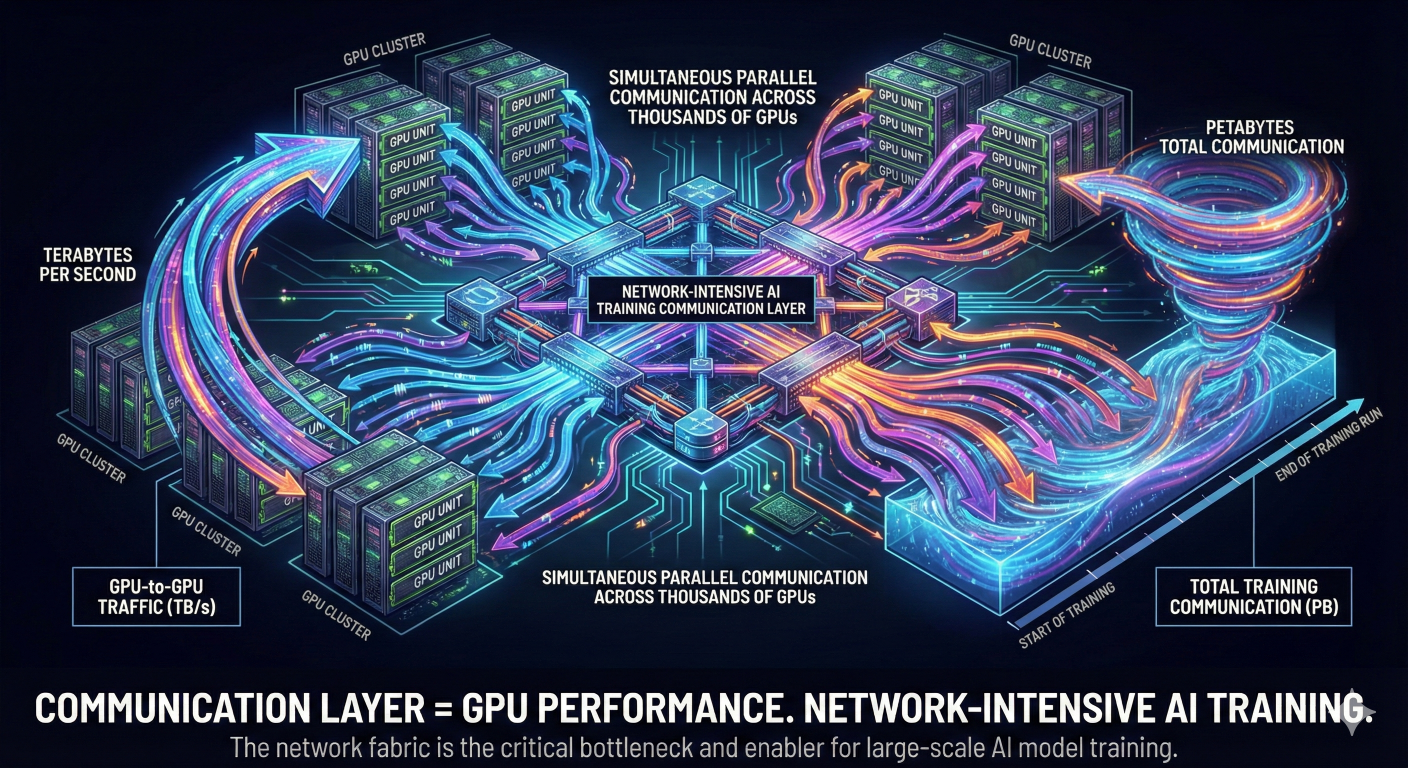
7. Why Training Takes So Long (Real Reason)
People often assume training takes months because:
8. What Comes Next in This Series
Now that we understand:
Sabyasachi
Network Engineer at Google | 3x CCIE (SP | DC | ENT) | JNCIE-SP | SRA Certified | Automated Network Solutions | AI / ML (Designing AI DC)
 Launch your Graphy
Launch your Graphy