In the previous part of this series, we explored the foundations of AI — models, training, GPUs and inference.
Now, let’s go one level deeper into the most important part of AI development:
👉 How raw data becomes intelligence.
👉 How language turns into numbers.
👉 How neural networks learn from tokens.
This entire journey starts with one core ingredient:The Training Set — also known as “The Prop Data”.
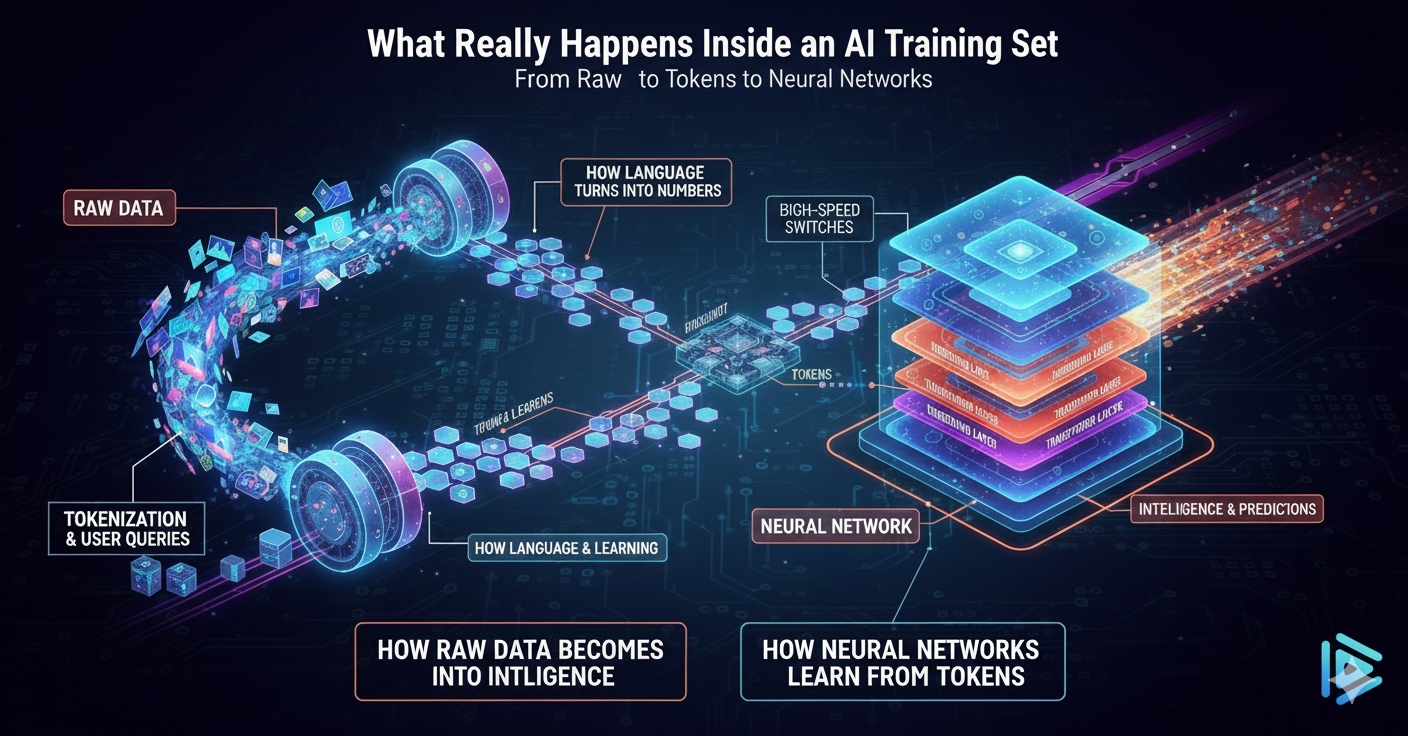
1. The Training Set: Where It All Begins
Every AI model — from ChatGPT to Gemini — is powered by a massive collection of data called the training set.This dataset includes:
- Wikipedia articles
- Web pages
- News articles
- Scientific papers
- Books and novels
- Conversations
- Public domain documents
- Domain-specific data like business logs
All of this isn’t just “collected.”
It’s carefully curated, cleaned, filtered, and organized so that the model can learn meaningful patterns.Think of the training set as the world of knowledge we present to the AI before it learns anything.
2. But AI Doesn’t Understand Language — So We Tokenize It
Here’s the interesting part:
AI models do not understand English, or Hindi, or any human language.They only understand numbers.So how do we convert human language into something a neural network can learn?Through a process called Tokenization.🧩 What is tokenization?Tokenization means breaking down language into small pieces called tokens.These tokens might be:
- complete words (“training”)
- subwords (“train”, “ing”)
- punctuation (“.”, “,”)
- even pieces of words (“inter”, “active”, “ness”)
The tokenizer decides how to chop text into meaningful units that a model can process.🧠 Why subwords?Because languages have structure.
For example:“Understanding” → “under + stand + ing”
“Prediction” → “predict + tion”By chopping words into subword patterns, AI can understand context even for words it has never seen before.Tokenization is the bridge between human language and mathematical representation.
3. Tokens Become Numbers — The Real AI Language
Once the training set is tokenized, each token is mapped to a unique ID number.This is where language becomes math.For example:
| Token | ID |
| “train” | 4711 |
| “ing” | 1120 |
| “model” | 2021 |
| “AI” | 75 |
The model never sees text.
It only sees streams of numbers representing tokens.This numeric sequence is what flows through neural networks.
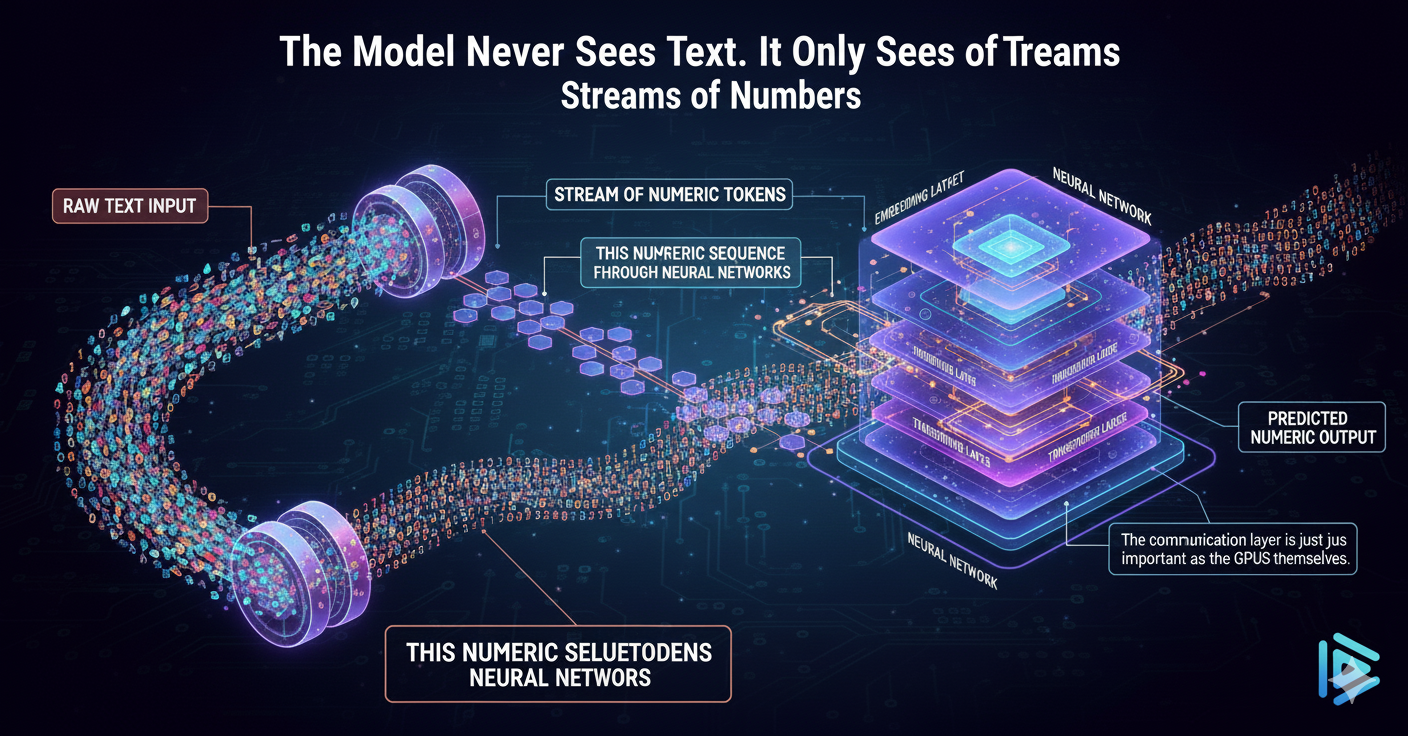
4. Enter the Neural Network: The Digital
BrainNow that we have:
- A training set
- Tokenized language units
- Numerical token IDs
We feed all of it into the neural network — the heart of an AI model.A neural network is inspired by the human brain:
- It has layers
- Each layer transforms information
- Neurons activate based on patterns
- Connections strengthen or weaken based on learning
This is what allows AI to:
- Learn grammar
- Understand context
- Recognize patterns
- Predict the next word
- Summarize text
- Answer questions
- Even generate creative ideas
Each token influences the next token through billions of learned parameters.
5. Why GPUs Are Essential in This Stage
Now comes the heavy lifting.The training process happens on GPU-accelerated devices — specialized hardware built specifically for:
- Extreme mathematical operations
- Large matrix multiplication
- Parallel compute execution
- Fast memory access
GPUs have:
- Embedded AI-specific software
- CUDA cores
- Tensor cores
- High-bandwidth memory
- Parallel compute units
All of these are needed because neural network training is intensely mathematical.Without GPUs, modern AI models would take decades to train.With GPUs, they can be trained in weeks or months.

6. The Training Loop: Where Learning Happens
Here’s what actually happens during training:
- Take a batch of tokenized data
- Run it through the neural network
- Compare the model’s output with the correct answer
- Calculate the error
- Adjust all the internal parameters
- Repeat millions or billions of times
This loop slowly shapes the model’s internal structure until it can:
- predict
- understand
- reason
- generate
Training transforms raw data → patterns → intelligence.
7. From Language to Tokens to Intelligence — The Full Pipeline
Let’s summarize the entire flow:
- Raw Data
(Books, web pages, articles, documents) - Training Set Creation
(Cleaning, filtering, formatting) - Tokenization
(Chopping language into tokens) - Numeric Conversion
(Token IDs) - Neural Network Training
(Billions of math operations) - GPU Acceleration
(Massively parallel computation) - AI Model Emerges
(A trained, intelligent system ready for inference)
⭐ Final Thoughts: The Hidden World Behind AI IntelligenceEvery time you ask an AI a simple question, you are interacting with the result of:
- trillions of mathematical operations
- millions of GPU hours
- billions of tokens
- a neural network with complex architecture
- and a deeply engineered training pipeline
AI may feel magical on the surface,
but underneath, it’s a beautiful combination of:data → language → tokens → math → models → intelligenceIn the next part of this series, we will go deeper into:👉 How the training loop actually works

👉 What “attention” means in transformers
👉 How models store knowledgeStay tuned — the real magic begins now.

 Launch your Graphy
Launch your Graphy