After an AI model is trained — after months of GPU-intensive computation, massive data exchange, and countless synchronization cycles — the next stage begins:👉 Inference
This is where the model finally comes alive and starts interacting with real users.While training builds intelligence, inference activates that intelligence.In this blog, let’s break down what actually happens after a model is developed, how it’s served to millions of people, and why the infrastructure requirements change dramatically between training and inference.
1. Once the Model Is Ready: How Do We “Activate” It?
Inference simply means:Taking a trained model and using it to answer real questions.This can happen in multiple ways:
- Directly through an API
- Embedded inside an app
- Integrated into a workflow
- Running on a phone or an edge device
- Serving millions of queries in a cloud infrastructure
But regardless of where it's used, the fundamental pipeline is the same.
A user sends a question or input → an agent prepares it → the model interprets it → the model generates an answer.
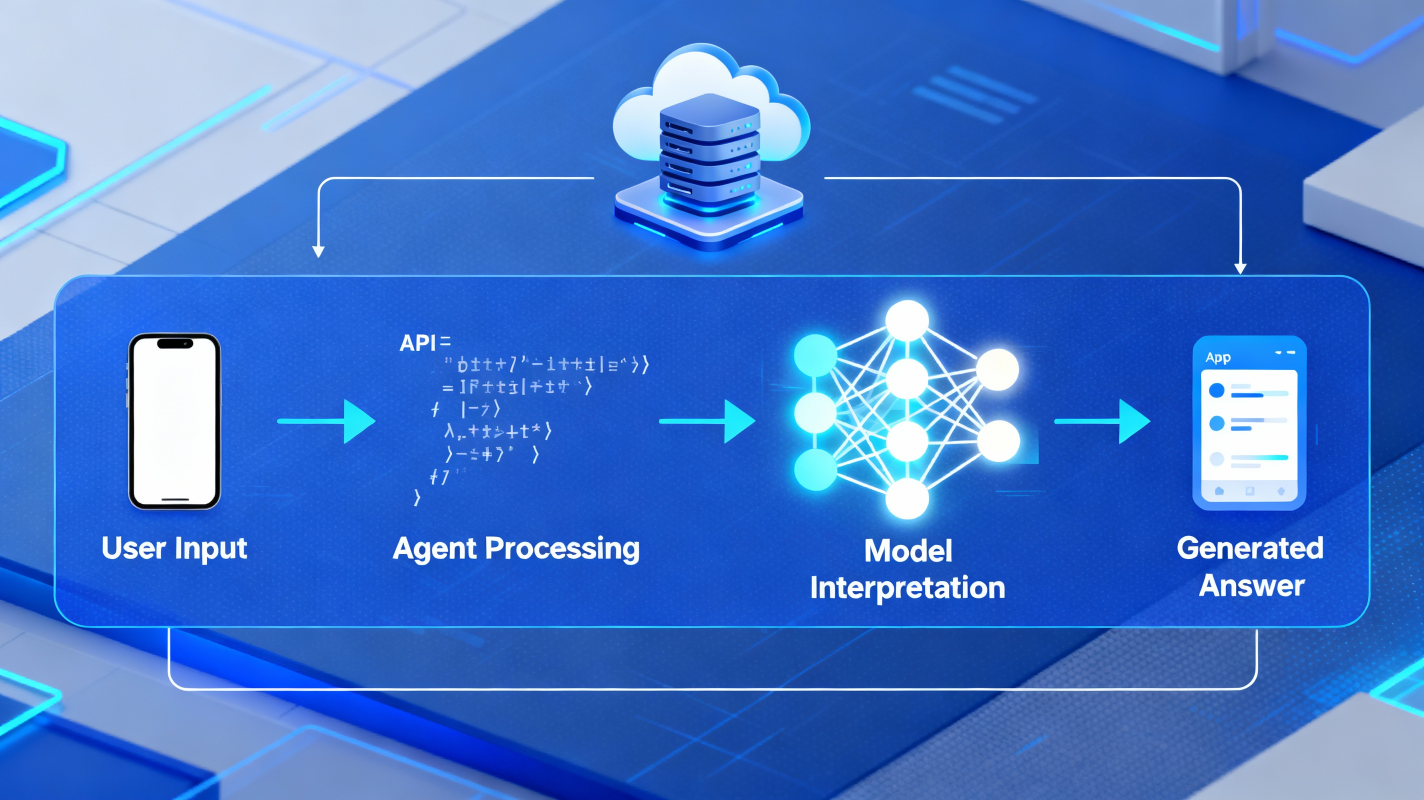
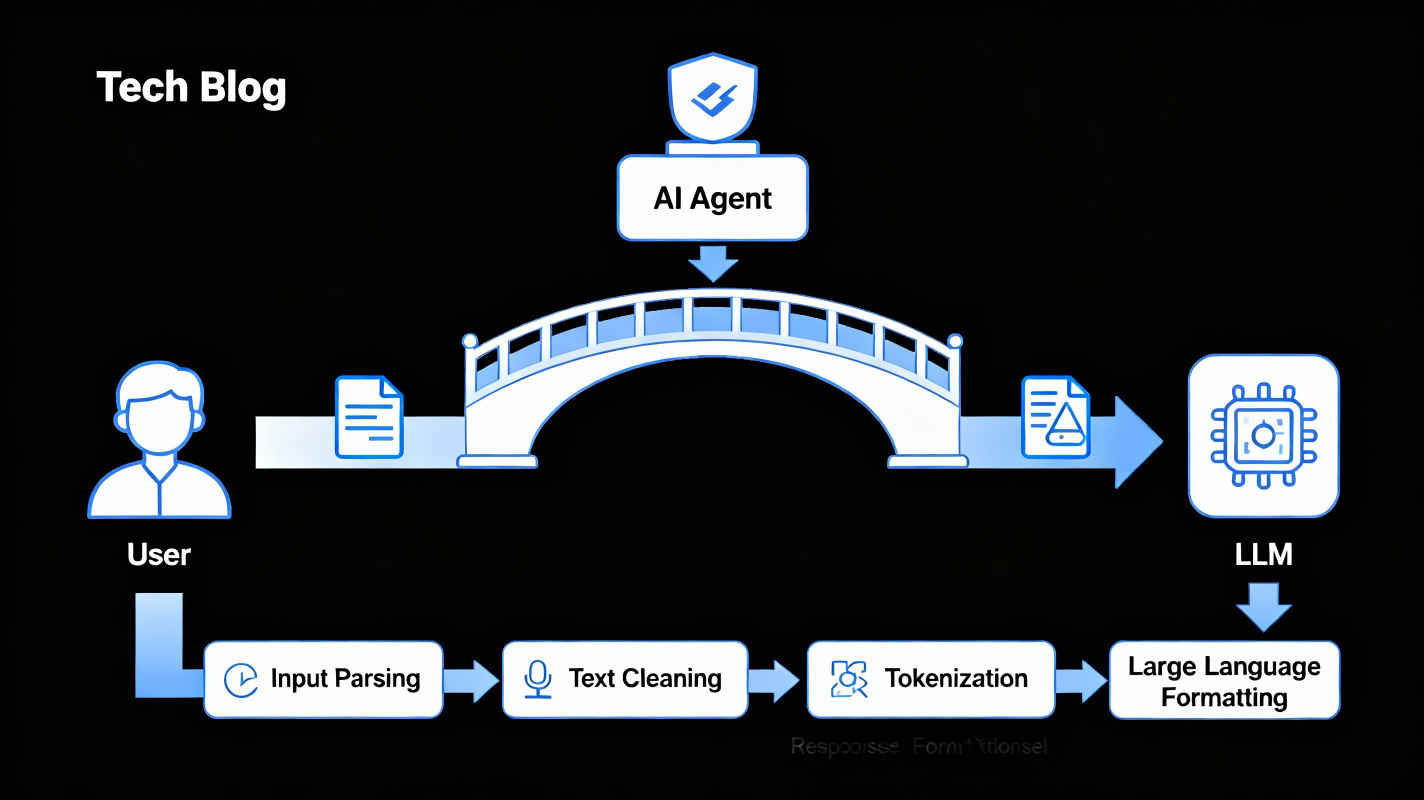
2. The Role of the Agent: Preparing the Question for the Model
Between the user and the model, there is always an Agent. The agent:
- Parses the user’s question
- Handles the instructions
- Performs preprocessing
- Cleans and tokenizes the text
- Sends the structured tokens to the model
- Interprets and formats the model’s response
- Sends the human-readable answer back to the user
When you ask a model a simple question like:
“Explain AI in simple terms.”
The agent already does a lot of work before the model even begins processing.
3. The Same GPUs, Same Neural Network — But Different Behavior
Even though inference uses the same components as training — same GPUs, same model, same networks — the requirements are completely different.
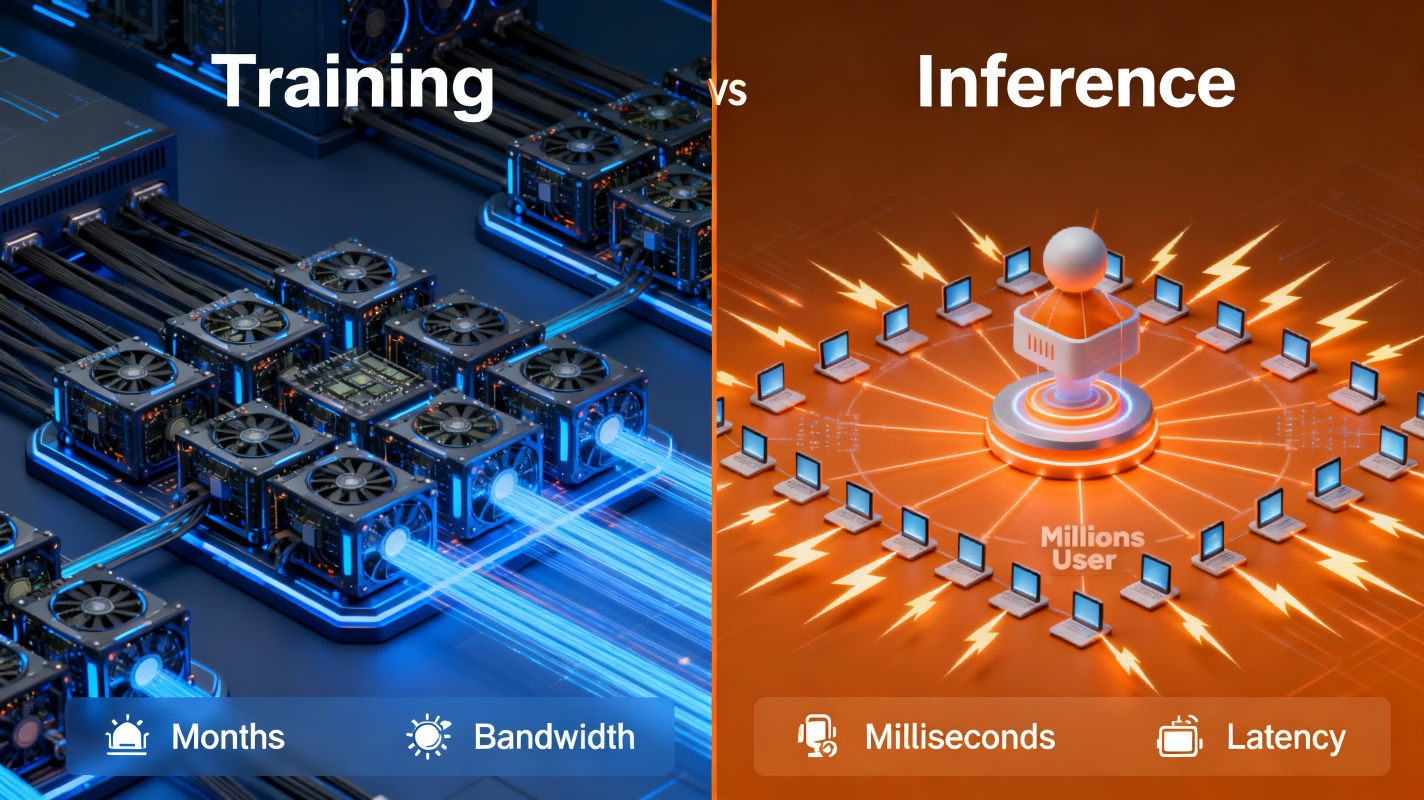
During Training:
- The model spans hundreds or thousands of GPUs
- GPUs exchange massive amounts of data
- Workloads are dense, parallel, and compute-heavy
- Synchronization is continuous
- Training takes weeks or months
- Bandwidth is the biggest requirement
During Inference:- The model may sit on many GPUs, or even on a phone
- Data exchanged between GPUs is extremely small
- Individual requests are short-lived
- Millions of users may access the model simultaneously
- Latency is the biggest requirement
Inference is all about speed, not volume.
4. Why Latency is Everything in Inference
When a model is serving users, the goal is simple:
👉 Respond as fast as possible.
That means:
- Very low GPU-to-GPU communication
- Ultra-fast token generation
- Sub-millisecond network latency
- In advanced systems — measuring latency in nanoseconds
When millions of users access the same model:
- Even 50ms extra latency per request can multiply into hours of wasted time
- Low latency allows more users to be served from the same infrastructure
- It improves model quality, responsiveness, and user experience
Training pushes bandwidth to the edge.
Inference pushes latency to the edge.

5. Why Models Still Need Multiple GPUs During Inference
Large models are huge.Some frontier LLMs are:
- 1 trillion parameters
- Spanning hundreds of gigabytes
- Distributed across many GPUs
But even smaller models on your phone can be:
Inference doesn’t require large communication waves —
but it still needs the model to sit across multiple GPUs or memory banks.
What changes is the workload pattern.

6. Two Ways to Think About AI Infrastructure
To build any AI system — or evaluate one — you must understand these two fundamental use cases:
✔ 1. Training:
- Months of continuous GPU compute
- Billions of tokens processed
- Heavy all-to-all GPU communication
- Extreme bandwidth needed
- Highly synchronized
- Expensive
- GPU utilization is the limiting factor
Bounding problem: Bandwidth
✔ 2. Inference:
- Milliseconds of compute
- Extremely light communication
- Millions of users
- Fast response needed
- Massive parallelism
- Latency becomes the key metric
Bounding problem: Latency
7. Why Understanding These Two Models Matters
If you're designing infrastructure, optimizing performance, or building AI applications, you must understand:
- Training requires compute + bandwidth
- Inference requires latency + scaling
- The networking fabric changes based on the phase
- Costs differ massively
- The engineering focus shifts from throughput → responsiveness
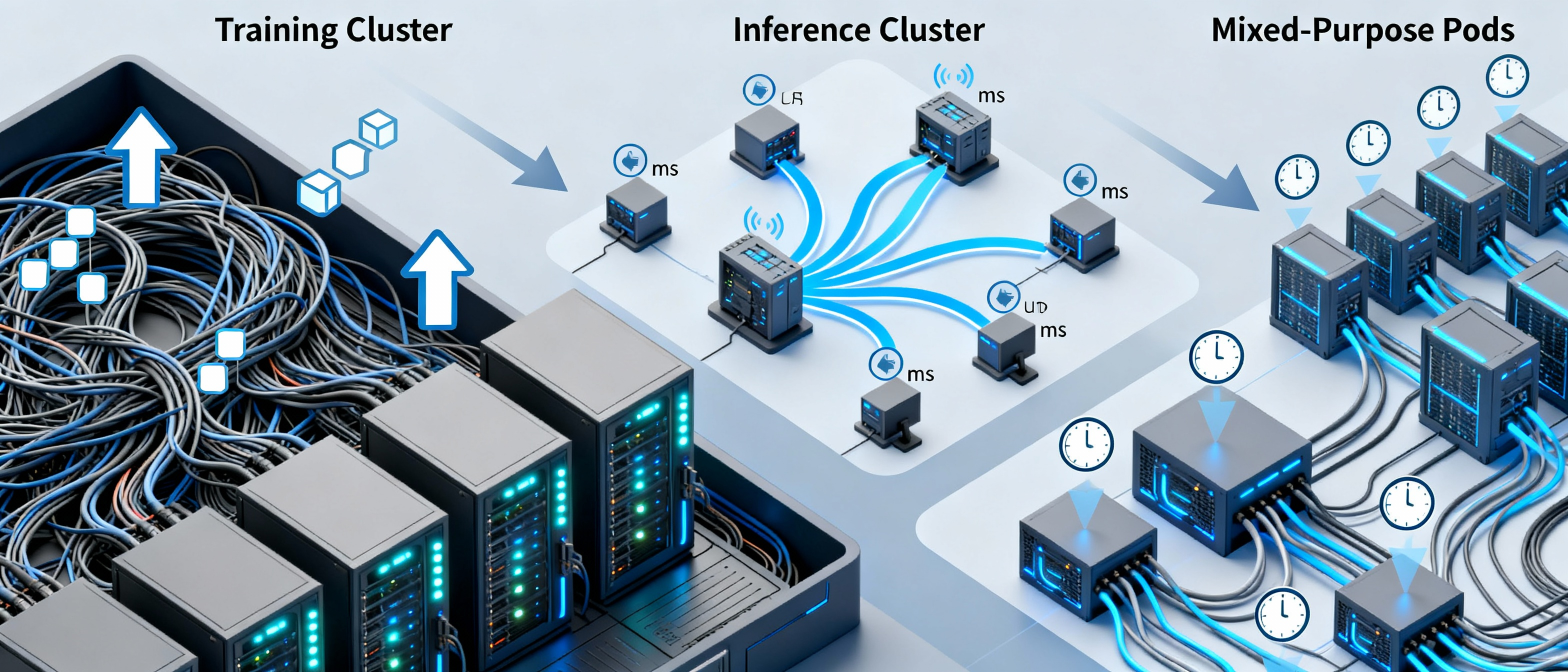
This is why AI datacenters have different architectures for:
- Training clusters
- Inference clusters
- Mixed-purpose GPU pods
Each one is optimized for a different bottleneck.
⭐ Final Thoughts
AI does not end with training —
that is only the beginning.Inference is where the model interacts with the world,
where intelligence gets activated,
where millions of people experience the output of thousands of GPU-hours.And understanding how inference works is essential for building:
- efficient AI systems
- responsive applications
- scalable architectures
- cost-effective operations
In the next part of the series, we will explore:👉 How AI inference is optimized at scale
👉 Why edge inference is rising
👉 How model quantization and distillation affect latency and cost
👉 How GPU clusters serve millions of real-time inference requestsStay tuned — the journey continues.

 Launch your Graphy
Launch your Graphy