There are no items in your cart
Add More
Add More
| Item Details | Price | ||
|---|---|---|---|

Sabyasachi (SK)
Lorem Modern data centers—whether built by Google, Meta, AWS, Microsoft, or Arrcus-based fabrics—use a Clos / Spine–Leaf architecture instead of traditional three-tier networks. The reason is simple:
👉 It scales horizontally.
👉 It delivers predictable low latency.
👉 It offers massive throughput and no single point of failure.
Let’s break this down in a way that would impress any Google, Arista, Cisco, or Arrcus interviewer.
1. What is a Clos / Spine–Leaf Architecture?
A Clos fabric (named after Charles Clos, 1950s) is a multi-stage switching topology designed to provide non-blocking, high-bandwidth connectivity using many small switches instead of a few big ones.The modern implementation is called:
✔ Spine–Leaf Architecture
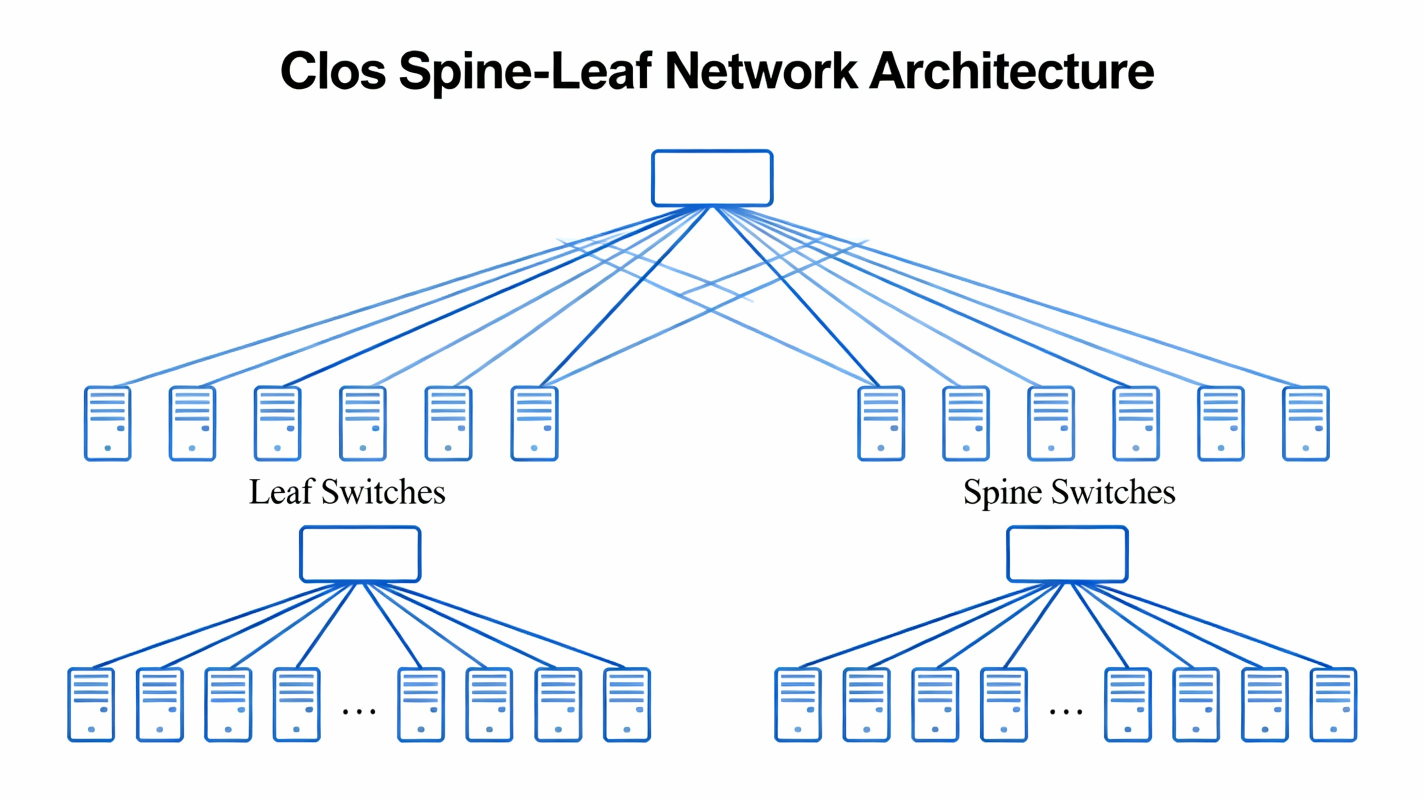
2. Why Traditional 3-Tier Networks Failed at Scale
Traditional networks used:
❌ Traffic bottlenecks between tiers
❌ North–south optimized, not east–west
❌ Limited bandwidth as link counts were fixed
❌ Scaling required expensive “big chassis” switches
But the modern data center needs:
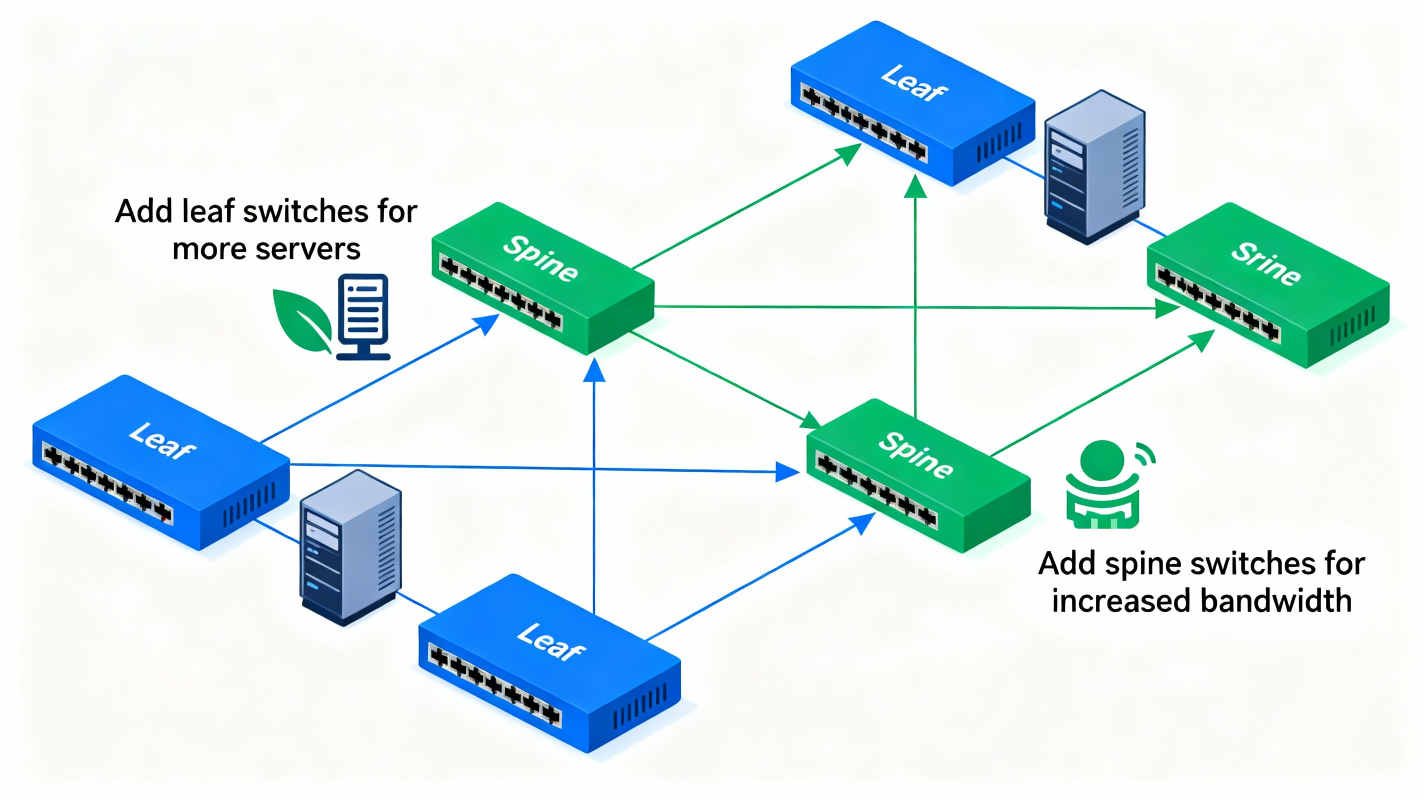
3. How a Spine–Leaf Fabric Actually Works
Leaf Switches
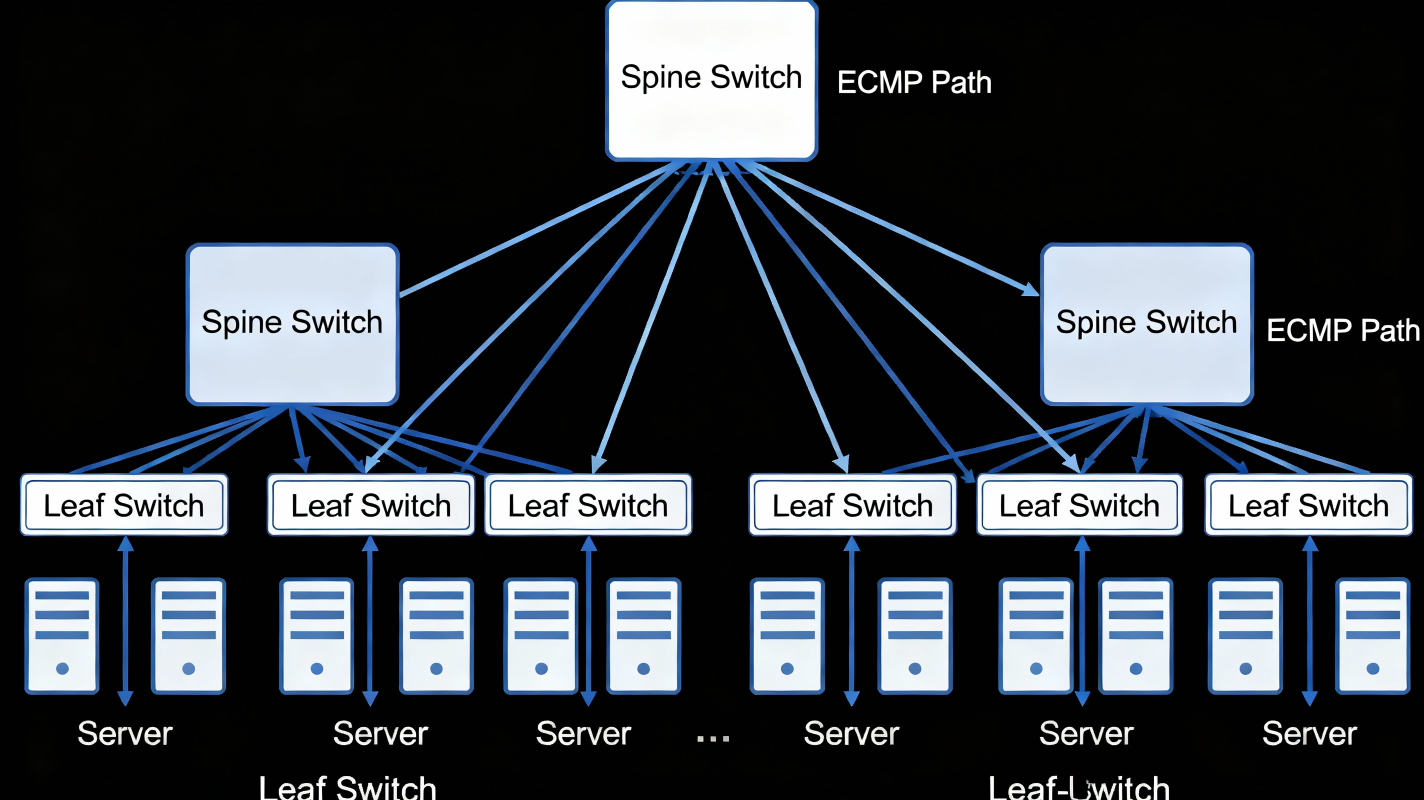
4. How Spine–Leaf Provides Massive Scale
🎯 A. Horizontal ScalabilityWant more servers?
➡ Add more leaf switches.Want more bandwidth?
➡ Add more spine switches.No need to replace expensive chassis.
Scaling is linear.Example:
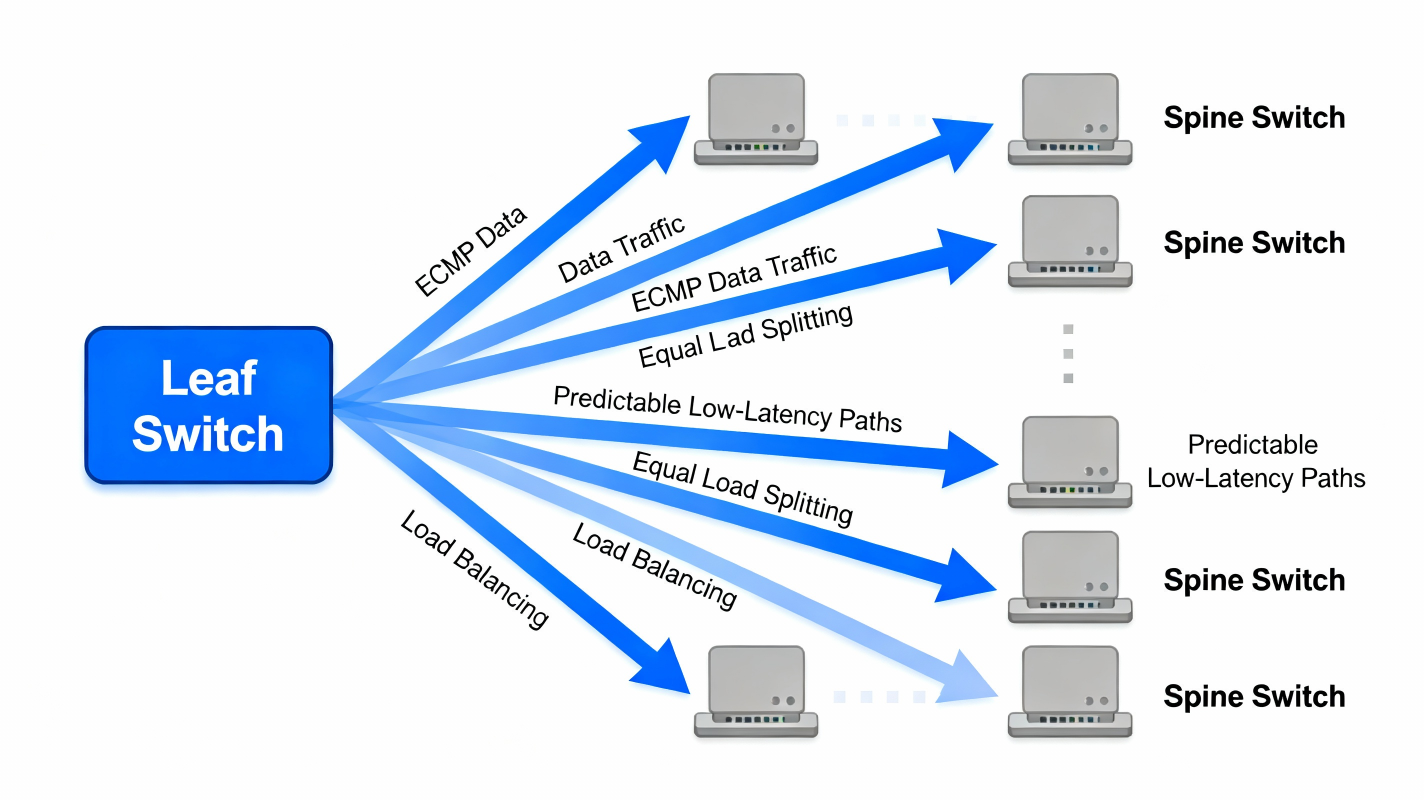
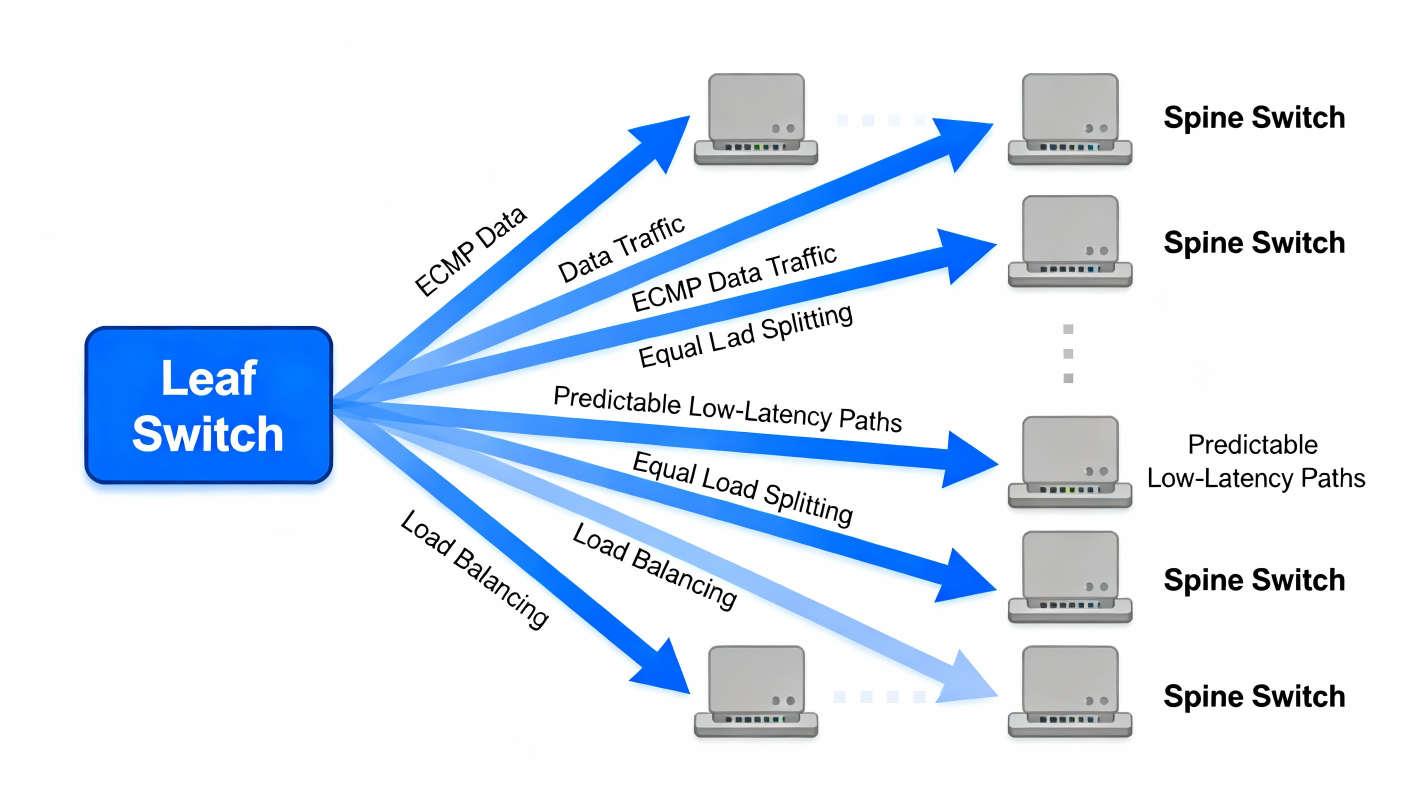
🎯 B. ECMP = More Bandwidth Automatically
Because every leaf connects to all spines, each path has the same cost (distance = 2 hops).
The fabric becomes:➡ Predictable
➡ Low-latency
➡ Multi-path load balanced
Using ECMP hashing, the network uses all paths simultaneously across:
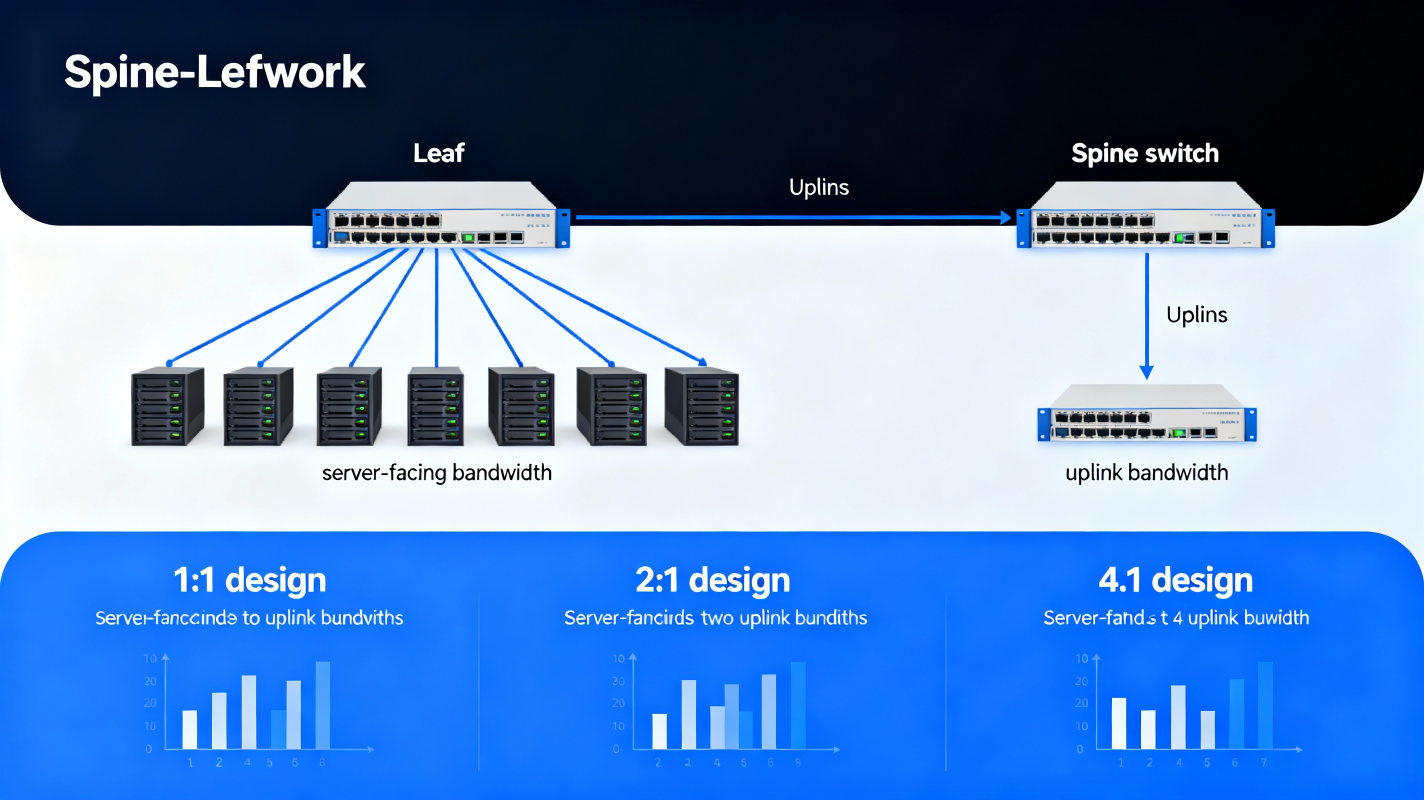
🎯 C. No Oversubscription (or predictable oversubscription)Oversubscription is:Server-facing bandwidth : Uplink bandwidth
In spine–leaf, you can design:
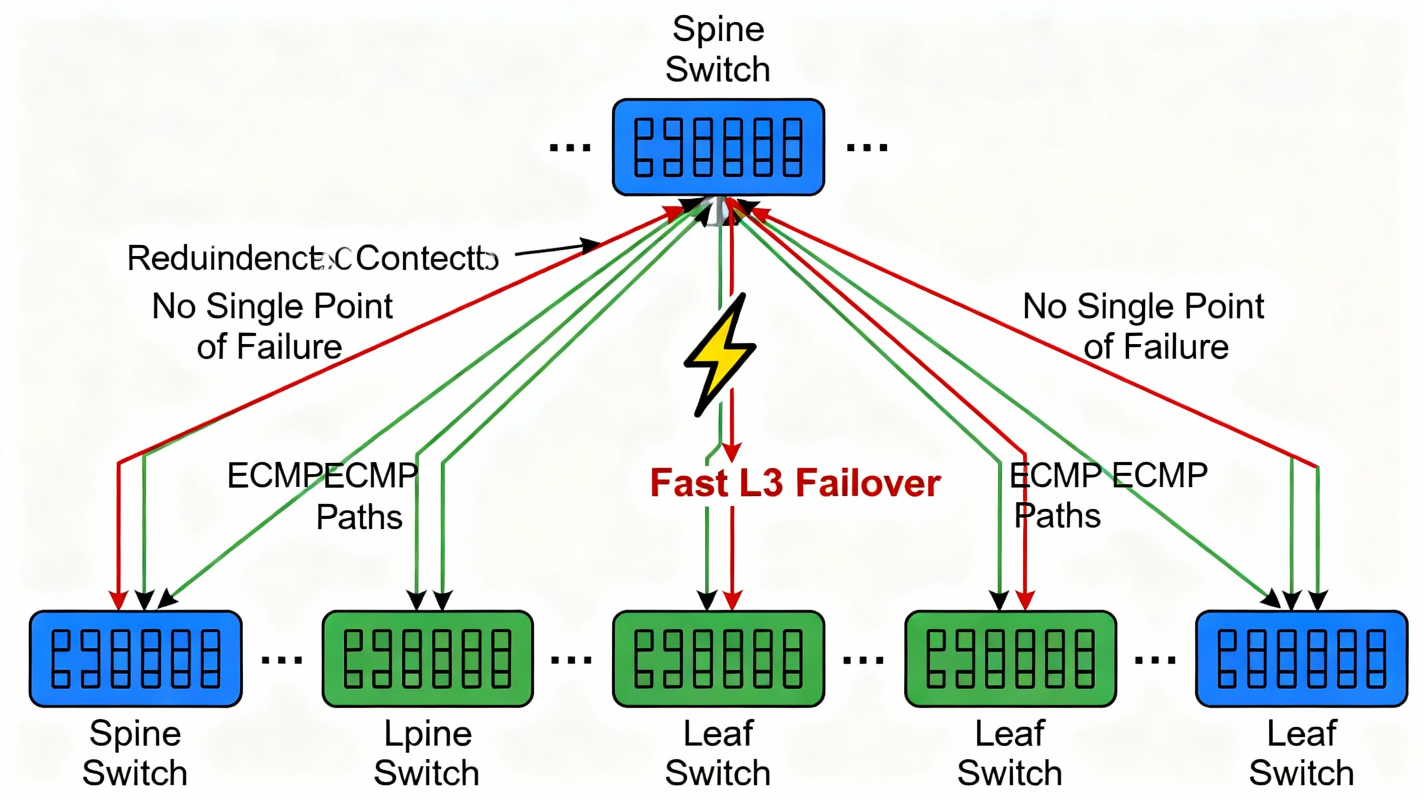
5. How Spine–Leaf Provides High Reliability
✅ A. No Single Point of FailureIn traditional networks:
✅ B. Fast Failover (Subsecond)
Because the fabric is built around L3 + ECMP, failure detection is fast:
✅ C. Simplified L3-only Core
Spines do not do:
6. Why Hyperscalers Love Clos / Spine–Leaf
✔ Amazon → Uses multi-stage Clos called “Scorpion”
✔ Google → Jupiter, B4 SDN WAN
✔ Microsoft → Clos-based Azure fabrics
✔ Meta → FBOSS + Wedge in store-and-forward Clos
✔ Arrcus ArcOS → Ultra-high performance ECMP Clos with ArcIQThe
reasons:
7. Putting It All Together — Summary Table
| Feature | Traditional Network | Spine–Leaf (Clos) |
| Traffic Pattern | North–South | East–West |
| Scalability | Limited | Massive, linear |
| Failure Impact | High | Minimal |
| Upgrade | Complex, disruptive | Add spines/leafs modularly |
| Bandwidth | Choke points | Predictable ECMP |
| Fabric Type | Tree | Clos Fabric |
Final Answer for an Interview (Concise Version)
A Clos / Spine–Leaf architecture provides scale by using many small switches connected in a multi-stage fabric where leaf switches connect to all spines, enabling horizontal scaling simply by adding more spines or leafs. Reliability comes from ECMP multi-pathing, where multiple equal-cost paths ensure traffic automatically reroutes during link or device failures. This eliminates bottlenecks, delivers predictable low latency, and removes single points of failure, making it the foundation of all modern data center networks.
How to configure?..Follow this
EVPN-VXLAN on Cisco Nexus Explained: L2VNI, BGP EVPN, OSPF Underlay & Full Config | EVPN VXLAN Nexus
Sabyasachi
Network Engineer at Google | 3x CCIE (SP | DC | ENT) | JNCIE-SP | SRA Certified | Automated Network Solutions | AI / ML (Designing AI DC)
 Launch your Graphy
Launch your Graphy